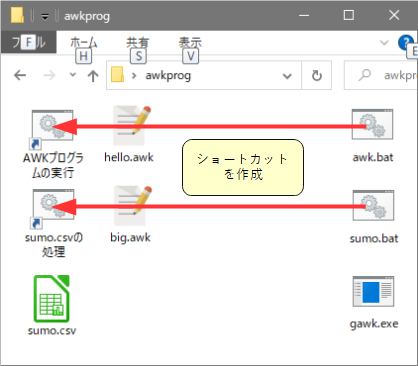
図1 awkprogフォルダの演習用ファイル
この資料は「例題で学ぶ簡易言語AWK」[2]を書き直したものです。Windows操作での利用も考慮しました。なお、コマンドプロンプトに不慣れな方は「パソコンのCUI操作」を参考にしてください。プログラミングの楽しさを味わっていただければ幸いです。本資料は Gentle Slope Systems(B.A.Myers) を意識しながら作成しました。
awkprog.zipを解凍し、デスクトップに置いてください(awkprog.zipはこちらからダウンロードできます)。awkprogフォルダの中には表1のようなファイルが入っています。
| ファイル名 | 内容 |
|---|---|
| gawk.exe | AWKインタープリタ(ver-3.1.7) |
| sort.exe | |
| hello.awk, big.awk | AWKサンプルブログラム |
| sumo.csv, hyaku.csv, jinko.csv, qanda.csv | CSVデータファイル |
| awk.bat, sumo.bat | Windowsで実行操作するためのバッチファイル |
Windowsではデフォルトで拡張子が表示されないようになっています。フォルダの、[表示][オプション]の「表示タブ」で詳細設定の中の[登録されている拡張子は表示しない]のチェックをはずしてください。
次に、操作の見通しをよくするために、awk.batのショートカットを作り、名前を「AWKプログラムの実行」としてください。同様に、sumo.batのショートカットを作り、名前を「sumo.csvの処理」としてください(図1)。
awkprogフォルダの中にhello.awkというファイルがあるので、メモ帳などのテキストエディタで開いて見てください(図2)。これは「Hello」と表示するAWKプログラムです。
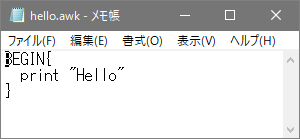
プログラムをメモ帳で作成する場合は、[ファイル][名前を付けて保存]操作の後、ファイルの種類を「すべてのファイル」、文字コードを「ANSI」にして保存します。
テキストエディタ Mery で作成する場合は、[ファイル][名前を付けて保存]操作の後、ファイルの種類を「すべてのファイル」、エンコードを「日本語(シフトJIS)」にして保存します。他の用途に差し支えなければ、[ツール][オプション]の[基本タブ]で、「既定のエンコード」を「日本語(シフトJIS)」、「行番号を表示」をチェック、「タブの桁数」を「2」にし、[記号タブ]で、「改行表示」と「全角空白表示」をチェックしておくとよいかもしれません。
また、hello.awkアイコンを右クリックし、[プロパティ]の[ファイルの種類]で変更ボタンを押し、メモ帳やMeryなどのテキストエディタを関連づけておくと、AWKファイル(拡張子がawkのファイル)をダブルクリックするとテキストエディタで開くようになるので便利です。
プログラミング言語はコンピュータが理解できる特別な言葉です。プログラミング言語を使ってコンピュータにさせたい仕事を記述したものがプログラムです。プログラミング言語には多くの種類があり、目的によって使い分けられますが、ここでは、AWKというプログラミング言語を用いてプログラムを作成します。AWKの名称は開発者であるAho, Weinberger, Kernighanの頭文字に由来します。
AWK言語は「ちょっとしたプログラム」を作る時に大変便利です。月刊アスキー1990年9月号の記事には、「Cなら1日かかるプログラムが5分で書ける」とあります。表になっているデータを入力して、データ処理をし、結果を表として出力するようなプログラムが得意です。グラフ機能はありませんが、必要な場合はAWKプログラムで処理した結果をExcelやgnuPlotやPythonなどグラフ機能を持ったソフトに渡してそちらで行います。
「AWKの解釈プログラム(gawk.exe)」は、AWK言語で書いたプログラムの1行ずつを解読しながら実行します。for文やprintf文などはほとんどC言語と同じで、C言語の簡易版と思ってもいいでしょう。
コマンドプロンプトを起動してください。黒い背景色の画面が現れます。ここで Alt + Enter の操作をしてみてください。ディスプレイ全体がコマンドプロンプトの画面になります。もう一度同じ操作をすると元に戻ります。Windows以前の、MS-DOSや、もっと前のCP/Mなどの時代はこのような画面でパソコンを使っていました。コンピュータに対する指示はキーボードから行い、結果はディスプレイに文字で表示されます。このような操作方法はCUI(Character User Interface)と呼ばれます。
さて、コマンドプロンプトを起動すると、カレントディレクトリは「C:¥Users¥ユーザ名」となります。ここで、cdコマンドでデスクトップのawkprogに移動し、dirコマンドでファイルの一覧を見てみます。以下、赤の下線はキーボード操作を表し、最後にEnterを押します。
C:¥Users¥ユーザ名>cd desktop C:¥Users¥ユーザ名¥Desktop>cd awkprog C:¥Users¥ユーザ名¥Desktop¥awkprog>dir ... C:¥Users¥ユーザ名¥Desktop¥awkprog> |
ファイル一覧を見ると、hello.awk があるのがわかります。図1と照らし合わせて見てください。
なお、表示文字を大きくしたい場合は、タイトルバーを右クリックし、プロパティの「フォント」タブでサイズを16~20程度にします。画面サイズも連動して大きくなります。「画面の色」タブで文字色や背景色を変えることもできます。
hello.awkは「Hello」と表示するAWKプログラムです。コマンド操作でメモ帳(notepad)で開くこともできます。
C>notepad hello.awk C> |
コマンド操作でhello.awkのプログラムを実行するには次のようにします。
C>gawk -f hello.awk Hello C> |
操作は、「gawk さんにお願いします。私が作った hello.awk というプログラムを解読して、そこに書かれたとおりに実行してください」と心を込めて行いましょう。
このようなコマンド操作は、たくさんのキーボード入力が必要なことから面倒と思われがちですが、そうでもありません。通常はプログラムを作ってすぐにうまく動作するわけではなく、何度もプログラムを修正しながら、完成にいたります。その時に、コマンド操作のヒストリー機能は大変便利です。
上記のような操作をした後に↑を押すと直前のキーボード操作が画面に現れ、Enterを押せば実行できます。↑を繰返し押せば、更に前のコマンド操作に戻ります。操作の内容を部分的に変更したければ←でカーソルを移動して修正できます。
Windows操作でプログラムを実行するには、下図(a)のようにAWKプログラムファイルhello.awkのアイコンを「AWKプログラムの実行」アイコンにドラッグ&ドロップします。すると、同図(b)のようにコマンドプロンプトの黒いウィンドウが開き、実行結果である「Hello」が表示されます。画面には「続行するには何かキーを押してください」とあるので、何かキーを押すとウィンドウが閉じます。
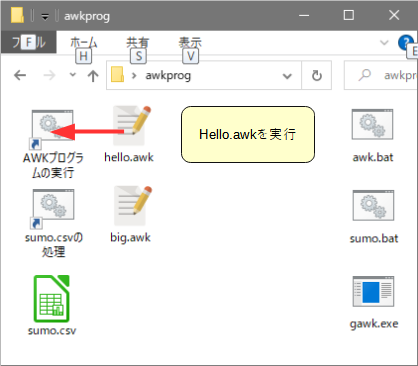 (a) 実行の操作 |
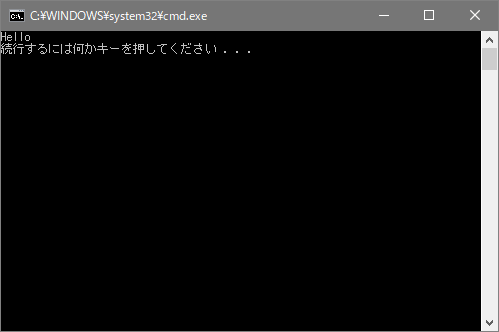 (b) 実行結果の表示 |
| 図3 Windows操作によるAWKプログラムの実行 | |
本資料は、コマンド操作で説明を行っていますが、このようにWindows操作でも行うことができます。この仕組みに興味のある方は awk.bat の中身を見てください。
(練習) プロクラム中の「Hello」の部分を「こんにちは」に替えて、プログラムを実行してみなさい。日本語がうまく表示できない場合は、hello.awkがシフトJISコード(メモ帳ではANSI)で保存されているか確認してください。
プログラム中に「 # 」が現れると、以後行末までコメントとなります。コメントはプログラムの実行に影響せず、プログラムの説明などを書きます。後から見直す時のために、次のように積極的にコメントを入れるようにします。
|
|
プログラムを作っても、意に反してうまく動作しないことはしばしばです。プログラムを作ったら、まずは思ったとおりにそのプログラムが動作しているかどうかを調べ、もしもうまく動作していなければ誤りを見つけて修正しなければなりません。
ここで、
|
|
のように、末尾の「 " 」を取って(入力し忘れて)、実行してみてください。すると、文法エラーとなり、誤りが指摘されます。ただし、いつも的確な表現で指摘してくれるとは限らないので、注意が必要です。
プログラムが正しく動作しない場合は、誤りの箇所を探し、修正して再度動作を確認します。正しく動作するようになるまで
| → |
|
を繰り返します。この作業はデバグと呼ばれます。「プログラムがうまく動作しないのは、そこに虫(バグ)が潜んでいるのが原因で、虫を退治(デバグ)すればプログラムが正しく動くようになる」というわけです。こう考えると幾分気が休まりますね。
デバグ時に、2.2で紹介したヒストリー機能は大変役に立ちます。
(練習) プログラムを次のようにわざと間違えて実行してみなさい。
AWK言語の魅力を実感できるよう、CSVデータの処理を紹介します。
awkprogフォルダの中に、歴代横綱の名前、出身地、身長、体重が「 , (カンマ)」で区切られた以下のようなデータファイル sumo.csv があります(sumo.csvはこちらからダウンロードできます)。テキストエディタで sumo.csv を開いて確認してください。
|
|
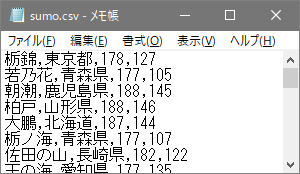
ここで、1行分に相当する1件のデータをレコードといいます。1番目のレコードは栃錦に関するデータです。名前、出身地、身長、体重の各項目のことをフィールドといいます。4番目のフィールドは体重のデータです。CSVデータは、レコード区切り文字 が「改行」、フィールド区切り文字 が「 , 」になっています。
次に、以下のように、big.awk というプログラムファイルを用意します。
|
|
BEGIN{ } の中の「 FS = "," 」は、これから読み込む入力データ(sumo.csv)の区切り文字(Field Separator)を「 , 」にしなさいという指示です。
「 $4>=150{ print $0 }」は、4番目のフィールド($4)が 150 以上のレコードについて、{ } 内の処理を実行しなさいという指示で、処理は「当該レコード($0)を表示しなさい」となっています。
sumo.csv のデータを big.awk のプロクラムで処理するには、以下のように操作します。
C>gawk -f big.awk sumo.csv ... |
この操作は、「gawk さんにお願いします。big.awk のプログラムを解読して、そこに書かれたとおりに sumo.csv のデータを処理してください」というような意味になります。より具体的には
ということを意味しています。実行結果を確認してください。
Windows操作で行いたい場合は下図のようにします。
(練習) 「身長($3)が180cm以上のデータ($0)を表示」するプログラム tall.awk を作成し、実行しなさい。また、「身長($3)が180cm以上の横綱の名前($1)を表示」するようにしてみなさい。
(練習) 上と同様の処理をExcelなどの表計算ソフトを用いて行ってみなさい。
データファイルはメモ帳などのテキストエディタを使って作成・編集します。Excelなどの表計算ソフトで作成し「CSV形式で保存」しても構いません。
データファイルを作る場合は、次のことに注意します。
さて、データファイルのどこを見ても「kg」とか「cm」などの単位は書かれていませんし、どこが体重の項目であるかも書かれていません。また、プログラムを見ても書いてありません。データがどのように格納されているかを知って、それに基づいてプログラムが作られるのです。データとプログラムの整合性が重要だということに注意してください。
(練習) テキストエディタで sumo.csv の最後に、あなたのデータを付け加え、big.awk で処理してみなさい。
上の例では実行結果は画面に表示されます。次のように、リダイレクト機能を使うと実行結果を画面に表示する代わりにファイルに格納することができます。
C>gawk -f big.awk sumo.csv >big.csv C>big.csv |
「 >big.csv 」を付け加えることにより、画面に表示されるはずの内容は big.csv というファイルに格納されます。続く「 big.csv 」の操作は必ずしも必要なわけではありませんが、この操作で big.csv を表計算ソフトで開くことができます(GUIのダブルクリックと同じ)。
2.6で取り上げたプログラムをもう一度みてみましょう。
|
|
$1~$4は1~4番目のフィールドを意味し、フィールド変数と呼ばれます。$0は全フィールド(行そのもの)になります。
「 BEGIN 」や「 $4>=150 」の部分をパターン、{ } で囲まれた部分をアクションといいます。AWKプログラムは
|
|
です。関数定義については7章で取り上げます。
big.awkの中はふたつの「パターン{アクション}」が並んでいると見ることができます。「パターン{アクション}」は
と読み、データファイルのレコードを1件(1行)読んでは「パターン{アクション}」を最後のレコードまで繰り返します。
特殊なパターンとして BEGIN と END があります。BEGIN はレコードの入力をはじめる前、END はすべてのレコードの処理が終った後に、それぞれ1度だけマッチします。これらは無くても構いませんし、データファイルのデータを処理するのでなければ、hello.awkのように BEGIN{ } だけという場合もあります。
上の例では、初めに FS (入力のフィールド区切り文字)を「 , (カンマ)」にし、その後、レコードを1件(1行)ずつ読んでは、「 $4>=150 」というパターンにマッチしていれば { } 内を実行します。
パターンとアクションのうちいずれかを省略することができます。パターンを省略すると、すべてのレコードにマッチします。つまり、
|
|
はすべての横綱のレコードを表示します。また、次のようにアクションを省略した場合は、「 print $0 」というアクションが仮定され、パターンにマッチするレコードが表示されます。
|
|
実行してみてください。
C>gawk -f big.awk sumo.csv ... |
BEGIN と END については、big.awk を以下のようにしてみると、その意味が理解できます。
|
|
実行してみてください。
C>gawk -f big.awk sumo.csv ... |
現在のレコードが何番目かは NR という変数に、現在のレコードがいくつのフィールドからなるかは NF という変数に自動的にセットされます。sumo.csv では、どのレコードも NF の値は4となるので、$4 の箇所は $NF としても同じです。
また、入力のフィールド区切り文字( FS )は初めはスペースまたはタブなのですが、データを読み始める前に BEGIN{ } の中で「 , (カンマ)」に変更しています。必要に応じて出力のフィールド区切り文字( OFS )も「 , 」に変更します。
NR, NF, FS, OFS のように予め名前と役割が決まっている変数を組み込み変数といいます。
肥満の判定に用いられるBMI(Body Mass Index)は次式で計算します。ただし、単位は身長[cm]、体重[kg]。
この値は下表のように判定されます。
| 19.8未満 | 19.8以上24.2未満 | 24.2以上26.4未満 | 26.4以上 |
| やせ | 普通 | 過体重 | 肥満 |
ここで、身長が170cm、体重が65kgの人のBMIを計算するAWKプログラム bmi.awk は次のように書くことができます。
|
|
このプログラムは次のように実行します。
C>gawk -f bmi.awk 22.4913 C> |
BMIの計算結果が「22.4913」と表示されます。
プログラムは、初めに変数 h (身長) に 170 を代入し、次に変数 w (体重) に 65 を代入します。「 = 」は左辺と右辺が等しいということではなく、「右辺の値を左辺(の変数)に代入しなさい」という意味です。次に、h と w の値からBMIを計算し、変数 BMI に代入します。
print で、値を表示し、改行します。
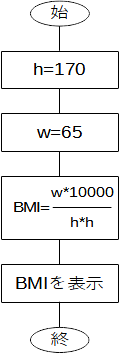
BEGIN{ } 内はAWK言語で表された「文」の並びになっていて、文は「...しなさい」という命令を表しています。基本的には記述した順に文が実行され、このプログラムはフローチャートで表せば下図のようになります。
{ } 内の文の並びは、上の例のようにインデント(字下げ)すると、プログラムの見通しが良くなります。字下げにはTABまたは半角スペースを使います。
文の末尾には「 ; (セミコロン)」を置きますが、省略しても構いません。ただし、1行に2つ以上の文を記述する場合は、「 h=170; w=65 」のように、文の末尾(文と文の間)に「;」を置きます。
2.5でエラーとデバグについて書きましたが、文法エラーとは別の種類の誤りもあります。それは、BMIを計算するプログラムで「10000」を「1000」と入力したような場合です。このような場合はコンピュータにとって誤りではなく、指示どおりに「正しく」計算し、その結果1桁違った結果が表示されることになります。このようなプログラム作成者の入力ミスや考え違いによって生じるエラーには特に注意が必要です。
(練習) プログラム中の「10000」の箇所を「1000」として、動作を確認しなさい。
変数はデータを入れる「箱」のことで、名前(変数名)が付けられます。宣言せずに突然変数を使いはじめることができ、0または空文字列("")に初期設定されます。変数名は、アルファベットで始まる英数文字列で、大文字と小文字は区別されます。2.9で出てきた NR, NF, FS, OFS など、予め名前と役割が決まっている変数を組み込み変数といいます。名前が重複しないよう、変数名にはなるべく小文字を使います。
「 h=170 」は、h という名前の変数に 170 という数値データを代入します。データの型には数値の他に、文字列があり、変数にはどちらの型のデータも代入できます。他の多くのプログラミング言語では、あらかじめ変数の使用を宣言したりデータの型を指定する必要があります。
変数 s に文字列データを代入する場合は、
のように、文字列データの部分を「 " (二重引用符)」で囲みます。
「 BMI=w*10000/(h*h) 」は、h の値と w の値からBMIを計算して変数 BMI に代入します。乗算を示す「 * 」や除算を示す「 / 」を演算子といいます。
「 5 + 10 」や「 x - y 」などは式と呼ばれ、演算子に従って左右の値に対して演算が行なわれ、その演算結果が式の値となります。式を組み合わせた場合には、どの演算から順に計算されるかは演算子の優先度により決まります。優先して計算させたい箇所は、「 BMI = w * 10000 / ( h * h ) 」のように ( ) で括ります。 [ ] や { } などの括弧は利用できず、二重三重にする場合もすべて ( ) を使います。「 = 」は代入演算子です。
文字列の演算には連結演算(または連接演算)があります。二つの文字列をくっつけて一つの文字列にする演算で、演算子は半角スペースを使います。たとえば、「 "標準" "体重" 」の演算結果は「 "標準体重" 」になります。次の例では、変数 z の値が「 "標準体重" 」という文字列になります。
bmi.awkを次のように変更して、動作を確認してください。
BEGIN{
h=170
w=65
BMI=w*10000/(h*h)
print "BMIは" BMI
}
|
変数 BMI には数値が代入されています。文字列と数値の連結演算はないので、このような場合は、BMI の値を文字列に変換してから文字列の連結演算が行なわれ、「 "BMIは22...." 」のような文字列となり、表示されます。このように、データの型は必要に応じて「都合良く(ときには都合悪く)」自動的に変換されます。
自動的な型変換は大変便利である反面、思わぬ落とし穴もあるので注意が必要です。変数 a のデータを明示的に型変換させるには、「 a * 1 」のように1を掛けて数値データにしたり、「 a "" 」のように空文字列と連結演算を行って文字列にします。
数値の大小関係を調べるには、関係演算子を用います。「 h > =180 」は身長( h )が 180 [cm]以上の場合に1(真)、そうでない場合は0(偽)になります。
BEGIN{
h=170
w=65
big=(h>=180)
print "BIG? " big
}
|
C>gawk -f big.awk BIG? 0 C> |
等しいかどうかを調べるには、「 h == 180 」のように「 == 」を用い、その値は1(真)または0(偽)となります。「 h = 180 」とすると h に 180 が代入され、式の値は 180 になってしまいます。
関係演算子は文字列にも適用され、「 "ABC" == "ABC" 」「 "A" < "ABC" 」「 "A" < "B" 」などが1(真)となります。「 "10" < "2" 」も1(真)となるので注意が必要です。
(練習) h (身長)を190にして実行して動作を確認しなさい。
(練習) w (体重)が80以上かどうか調べるようにし、w の値を変えて動作を確認しなさい。
論理式や論理値を組み合わせて複雑な条件を表現するには「 && (AND)」「 || (OR)」「 ! (NOT)」の論理演算子を用います。
「 ( h >= 180 ) || ( w >= 70 ) 」は、身長( h )が 180 [cm]以上、または体重( w )が 70 [kg]以上の場合に1(真)、そうでない場合は0(偽)になります。
BEGIN{
h=170
w=65
big=(h>=180)||(w>=70)
print "BIG? " big
}
|
実際にはこのように論理値をそのまま表示させることはなく、比較演算や論理演算は主に後出のif文やfor文の条件を表現する際に用います。
論理演算を表で表せば以下のようになり、これを真理値表といいます。
|
|
|
(練習) h (身長)や w (体重)を変えて動作を確かめなさい。
(練習) h (身長)が180以上かつ w (体重)が70以上の時に 1 が表示されるようにし、h や w の値を変えて動作を確認しなさい。
これまでは、print文を使って計算結果を表示してきました。
print文の他にprintf文があり、printf文を使うと行末の改行が行われません。その他、printf文を使うと、さまざまな書式指定が可能となります(付録A)。
print文やprintf文で表示する文字列の中には、「¥n」(改行)や「¥t」(タブ)などの特殊文字を含めることができます。
print文やprintf文は、画面に表示されますが、「出力のリダイレクト機能」を利用するとファイルに格納することができます。その場合は
のようにします。これにより、画面には何も表示されず、代わりに"hello.txt"というファイルが作られ、その内容が「Hello」になります。
のようにします。既に"hello.txt"というファイルがある場合は「上書き」されるので、大事なファイルを消してしまわないように注意する必要があります。
とすると、既に"hello.txt"というファイルがある場合は、その内容に「Hello」が「追記」されます。
なお、プログラム中にリダイレクトの記載はせずに、実行時に以下のようにリダイレクト(上書きまたは追記)することもできます。
C>gawk -f hello.awk >hello.txt C> |
これまでは、プログラムの中で身長や体重の値を決めていました。今度は、身長と体重を入力し、それらの値からBMIを計算して表示してみます。
以下では、getline文と「入力のリダイレクト機能」を組み合わせて文字入力を行っています。
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=w*10000/(h*h)
print "BMIは " BMI
}
|
C>gawk -f bmi.awk 身長? 170 体重? 65 BMIは 22.4913 C> |
「 getline h<"con" 」で、キーボード( "con" )から入力した文字列を変数 h に代入します。"con" はキーボードを示す特殊なファイル名です。単に「 getline h 」とすると、実行時に指定したデータファイルから1行入力し、h に代入することになります。
なお、「体重?」を表示する際に「 printf 」を使い、改行しないようにしています。
(練習) 次のように、初めに2つの数を入力し、さまざまな演算結果を表示するプログラムを作りなさい。
C>gawk -f calc.awk x? 3 y? 2 3+2=5 3-2=1 3*2=6 3/2=1.5 3%2=1 3^2=9 3 2=32 C> |
(練習) 上記を参考に、別の題材のプログラムを作りなさい。
bmi.awkを次のように変更して、動作を確認してください。
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=w*10000/(h*h)
BMI=int(BMI+0.5)
print "BMIは " BMI
}
|
C>gawk -f bmi.awk 身長? 170 体重? 65 BMIは 22 C> |
ここで、「 int(x) 」はxの値を「小数点以下で切り捨てる」組み込み関数で、四捨五入するために「 x = int( x + 0.5 ) 」としています。
この場面では、小数点以下1桁まで表示させたいところです。これは「10倍した値を小数点以下で四捨五入し、その結果を10で割る」という工夫で実現することができます。次のようにプログラムを変更し、動作を確認してください。
... BMI=int(BMI*10+0.5)/10 ... |
ここでは、オリジナルの関数を作ります。bmi.awkを次のように変更してください。
function bmicalc(h,w){ # 身長(h)と体重(w)からBMIを求め小数点以下1桁で返す
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=bmicalc(h,w)
print "BMIは " BMI
}
|
実行してみてください。
C>gawk -f big.awk ... |
「 function bmicalc(h,w){...} 」では bmicalc という関数を定義し、「 BMI=bmicalc(h,w) 」でその関数を呼び出し、戻り値を利用しています。関数定義は
のように書きます。引数の並びは「 , (カンマ)」で区切ります。上の例では、呼び出し時に h と w の値を引数として渡し、関数定義の箇所ではそれらの値を h と w の変数に受け取っています。引数が無い場合もあります。
関数定義の {...} の中が複数の文からなる場合は順に実行され、{...} の中を最後まで実行するか、またはreturnが現れると、呼び出された箇所に戻ります。上の例のように、
を実行すると「値」を関数の値として戻ります。戻り値を必要としない場合もあります。
プログラムは書かれた順に実行されるのですが、関数定義の部分は例外で、その関数が呼び出されたときに実行されます。
関数を定義することにより、プログラムの見通しが良くなります。また、この例では定義した関数を1度しか呼び出していませんが、関数を複数箇所で呼び出すような場合に関数の定義が効果を発揮します。なお、関数はそれを作る時点で役割が明確になっているので、後々のために上の例のようにコメントを記載しておくようにします。
定義した関数が呼び出されることがなくても構いません。
なお、関数の中で計算途中の値を格納している変数 x はこの関数の外のどこかで使ってなければいいのですが、もしもどこかで使っていたりすると、そちらの値を書き換えてしまうことになります。そのような心配を払拭するには、関数定義の初めで
のように、x を局所変数として宣言します。これにより、変数 x はこの関数内でのみ有効となり、どこかで同じ変数名 x を使っていたとしても、異なる変数として扱われます。このようにしないと広域変数となり、この関数の外で同一の変数名を使った場合に、その値が書き換えられて不都合が生じてしまう恐れがあります。関数内で一時的に使うことが明らかな変数は、局所変数とすることにより、思わぬミスを未然に防ぐことができます。なお、関数定義の引数として用いられる変数 h と w も局所変数となります。
定義した関数の中には、別のプログラムでも利用できるものがあるかもしれません。そのような関数は、ライブラリとして別ファイルにすると便利です。定数を定義したい場合は BEGIN{ } の中で変数に値を代入しておきます。
以下は、bmicalc( ) が lib.awk の中で定義されていた場合の例です。
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=bmicalc(h,w)
print "BMIは " BMI
}
|
実行時には次のように lib.awk も指定します。
C>gawk -f lib.awk -f big.awk ... |
lib.awkの中に、ここでは使わない関数がいろいろ定義されていたとしても、それは構いません。
BMI値が26.4以上の場合「肥満」と判断されます。bmi.awkの「 print ... 」の箇所を次のように変更してください。
function bmicalc(h,w){
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=bmicalc(h,w)
if(BMI>=26.4) print "●" BMI
}
|
実行してみてください。
C>gawk -f big.awk ... |
「 if(BMI >= 26.4) ... 」の箇所は、( )内が1(真)の時(この場合は「 BMI >= 26.4 」が1(真)の時)に●が表示されます。
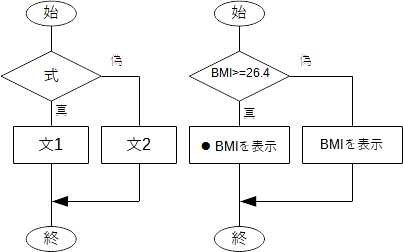
if文は
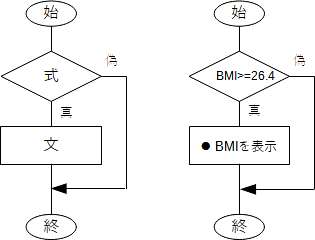
と書き、フローチャートで表せば、一般には下図左、ここでの例に関しては同図右のようになります。
このままでは、「 BMI >= 26.4 」が1(真)でない場合には何も表示されません。そこで、次のようにさらに1行追加してください。
function bmicalc(h,w){
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=bmicalc(h,w)
if(BMI>=26.4) print "●" BMI
else print " " BMI
}
|
追加した部分は「 BMI >= 26.4 」が1(真)でなければ、無印で表示するというものです。
実行してみてください。
C>gawk -f big.awk ... |
この場合のif文は
と書き、フローチャートで表せば、一般には下図左、ここでの例に関しては同図右のようになります。
このように、条件によって処理の内容を変えることができます。もしも、ある条件を満たしたとき、あるいはそうでないときに、複数の文を実行させたい場合は次のようにします。
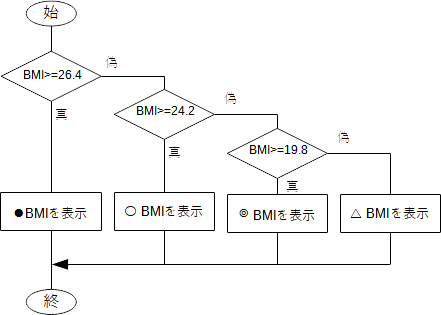
上の例では、if文を使って2つの場合分けをしたわけですが、もっと細かく場合分けしたい場合もあります。BMI値が26.4以上ならば●、24.2以上26.4未満ならば○、19.8以上24.2未満ならば◎、19.8未満ならば△をそれぞれ表示させてみましょう。●については既に正しく動作するので、「 BMI >= 26.4 」が0(偽)の場合について更に場合分けをすれば良いことになります。if文を組み合わせて次のようにします。
function bmicalc(h,w){
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=bmicalc(h,w)
if(BMI>=26.4) print "●" BMI
else if(BMI>=24.2) print "○" BMI
else if(BMI>=19.8) print "◎" BMI
else print "△" BMI
}
|
フローチャートで表せば、下図のようになります。例えば「〇」の表示は、BMIが26.4未満24.2以上であることがわかります。
ここで、関数定義の復習になりますが、BMIの値に応じた記号を返す関数 mark( ) を定義し、次のようにしてみます。関数定義を使って機能を独立させることにより、プログラムの見通しが良くなります。
function mark(x){ # BMIの値に応じて●○◎△の記号を返す
if(x>=26.4) return "●"
else if(x>=24.2) return "○"
else if(x>=19.8) return "◎"
else return "△"
}
function bmicalc(h,w){
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
printf "体重? "
getline w<"con"
BMI=bmicalc(h,w)
print mark(BMI) BMI
}
|
結果は変わりませんが、実行してみてください。
C>gawk -f bmi.awk ... |
(練習) ●○◎△のような記号ではなく、値に応じて次のようにメッセージを表示させてみなさい。なお、文字列の途中で改行させたい場合は、特殊文字「¥n」を使います。
C>gawk -f bmi.awk 身長? 170 体重? 65 あなたのBMIは22.4で判定は「普通」です。 このままの状態を維持しましょう。 C> |
以下は、はじめに身長を入力し、その身長に対するBMIの値を体重5kgきざみで計算して表示するプログラムです。
function bmicalc(h,w){
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
w=40
while(w<=80){
BMI=bmicalc(h,w)
print w ": " BMI
w=w+5
}
}
|
実行すると以下のようになります。
C>gawk -f bmi.awk 身長? 170 40kg: 13.8 45kg: 15.6 50kg: 17.3 55kg: 19 60kg: 20.8 65kg: 22.5 70kg: 24.2 75kg: 26 80kg: 27.7 C> |
while文は
と書き、( ) 内の「式」が真である限り何度でも、「文」を繰り返し実行します。フローチャートで表せば、一般には下図左、上の例に関しては同図右のようになります。
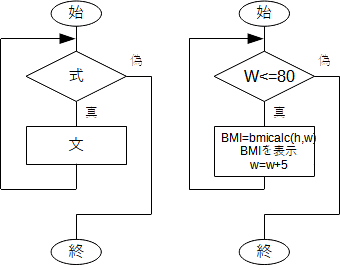
初めに w を 40 にしています。そして、「 w <= 80 」が真である限り { } 内を繰り返し実行します。{ } 内の最後でwの値を5ずつ増やしているので、 w はいずれ 85 になり、その時点で条件を満たさなくなり、繰り返しを終了します。
上の例のように、繰り返しのプログラムでは、初期化( w = 40 )と条件調べ( w <= 80 )と更新( w = w + 5 ) の3点セットが頻繁に登場します。この部分をまとめて書くようにしたのがfor文です。上の例はfor文を使って次のように書くことができます。動作は同じです。
function bmicalc(h,w){
x=w*10000/(h*h)
return int(x*10+0.5)/10
}
BEGIN{
printf "身長? "
getline h<"con"
for(w=40; w<=80; w=w+5){
BMI=bmicalc(h,w)
print w ": " BMI
}
}
|
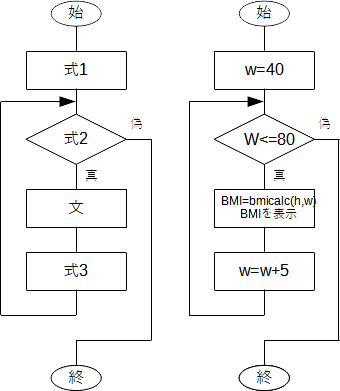
for文は
と書き、はじめに「式1」を実行し、「式2」が真である限り何度でも、「文」を実行しては「式3」を実行します。フローチャートで表せば、一般には下図左、ここでの例に関しては同図右のようになります。
(練習) 正の整数を入力し、1からその値まで足した値を表示するプログラムを作りなさい。
(練習) 半径に対する面積と体積の表を作りなさい。
5人の横綱の身長が、変数 h1 ~ h5 に用意されている時に、平均身長 mh を求めて表示するプログラムは以下のようになります。
BEGIN{
h1=178; h2=177; h3=188; h4=188; h5=187
mh=( h1 + h2 + h3 + h4 + h5 ) / 5
print "身長の平均は" mh
}
|
実行すると以下のようになります。
C>gawk -f heikin.awk 身長の平均は183.6 C> |
では、5人ではなくて100人だとどうでしょうか。h1~h100に値が用意されていたとしても、それらは別々の変数なので、その平均を求めるためには以下のようにすべての変数名を明記しないといけません。
mh=( h1 + h2 + ... + h100 ) / 100 |
これは現実的ではありません。
このように、データ数が多い場合は変数の一種である配列を使います。配列の場合、ひとつの変数に複数のデータを格納できます。
|
|
のように値を代入すると、1番目のデータ 178 は h[1]、2番目のデータ 177 は h[2] で参照できます。[ ] 内の番号を添え字(index)といいます。
配列を使うと、順番にデータを扱うことが可能になり、for文で添え字( i )を変化させ、次のように平均身長を求めることができます。今の場合、i は1から5まで変化します。
BEGIN{
h[1]=178; h[2]=177; h[3]=188; h[4]=188; h[5]=187
sum=0
for(i=1; i<=5; i=i+1) sum=sum+h[i]
mh=sum/5
print "身長の平均は" mh
}
|
実行すると以下のようになります。
C>gawk -f heikin.awk 身長の平均は183.6 C> |
100人分のデータであったとしても(それをどうやって用意するかは別にして)、プログラムは5を100に替えるだけですみます。
以下は、sumo.csvに入っている横綱のデータから一旦身長の配列データを作り、それをもとに平均を計算して表示する例です。
BEGIN{ FS="," }
{ h[NR]=$3 }
END{
sum=0
for(i=1; i<=NR; i=i+1) sum=sum+h[i]
mh=sum/NR
print "身長の平均は" mh
}
|
実行すると以下のようになります。
C>gawk -f heikin.awk sumo.csv 身長の平均は183.6 C> |
配列の添え字は1~の番号でしたが、添え字を文字列で扱うのが連想配列です。
横綱の体重データを
|
|
のように用意すると、栃錦の体重127は w["栃錦"] で参照できます。
以下の例では、sumo.csv のデータを読んで連想配列 w を作ります。そして、ENDのfor文「 for(name in w) 」で連想配列 w の添え字がひとつずつ name に代入され、print が繰り返されます。ただし、取り出す順番は定まっていません。
BEGIN{ FS="," }
{ w[$1]=$4 }
END{
for(name in w) print name ":" w[name]
}
|
実行すると以下のようになります。
C>gawk -f taiju.awk sumo.csv 照ノ富士:184 稀勢の里:171 白鵬:155 ... C> |
以下は、すべてのデータを表示するのではなく、名前を入力するとその横綱の体重を表示するようにしたものです。
BEGIN{ FS="," }
{ w[$1]=$4 }
END{
while(1){
printf "名前? "
getline name<"con"
if(name=="") break
if(name in w) print name "の体重は" w[name] "です"
else print name "のデータはありません"
}
}
|
while(1){...} の箇所は、{ } の中の処理を何度でも繰り返します。「 名前? 」と表示した後、getline で入力した文字列が変数 name に入ります。次に、入力した文字列が空文字列の時(改行のみ行った場合)に break で while(){ } から抜け出ます。通常は、入力した名前がデータにあるかを if(name in w) で調べ、あれば名前と体重を表示し、なければ「ありません」を表示します。
実行すると下記のようになります。
C>gawk -f taiju.awk sumo.csv 名前? 隆の里 隆の里の体重は155kgです 名前? 北の里 北の里のデータはありません 名前? 北の湖 北の湖の体重は150kgです 名前? ...改行のみで終了 C> |
以下は、連想配列を使って出身地別の人数を数えて表示するプログラムです。
BEGIN{ FS="," }
{ ninzu[$2]++ }
END{
for(ken in ninzu) print ken ":" ninzu[ken]
}
|
「 ninzu[$2]++ 」は、sumo.csvから1行(1レコード)ずつ読んでは出身地($2)を添え字とする連想配列 ninzu[$2] に1を加えます。全レコードを読み終わった時点で、ninzu["青森県"] は5、ninzu["長崎県"] は1、...になっています。
そして、for文で、ken に配列 ninzu の添字がひとつずつ代入され、print が繰り返されます。
データを読んでみないと「どんな出身地が現れるかわからない」わけですが、うまく処理することができます。
C>gawk -f syussin.awk sumo.csv 青森県:5 長崎県:1 三重県:2 ... C> |
前項で、出身地別に人数を表示することができましたが、これを簡易棒グラフで表示してみましょう。AWK言語にグラフィック機能は無いので、人数分だけ横に*印を並べることにします。プログラムは次のようにします。
BEGIN{ FS="," }
{ ninzu[$2]++ }
END{
for(ken in ninzu) print ken rep("*",ninzu[ken])
}
function rep(a,n){
s=""
while(n-- >0) s=s a
return s
}
|
定義した関数 rep(a,n) は a という文字列を n 個繰り返した文字列を返すようになっています。rep("A",4) は "AAAA"、rep("AB",3) は "ABABAB" を返します。
rep() の関数定義の中では while 文を用いて a を n 個連結した文字列 s を作成し、関数の値として返しています。
実行結果は下記のようになります。
C>gawk -f syussin.awk sumo.csv 青森県 ***** 長崎県 * 三重県 ** ... C> |
rep() の関数定義を、次のように再帰による関数定義に書き換えてみましょう。
...
function rep(a,n){
if(n==0) return ""
else return rep(a,n-1) a
}
|
これは、rep("A",4) として呼び出された場合、rep("A",3) と "A" を連結した文字列を返せばよいと考えるものです。関数定義の中で定義途中の自分自身を呼び出していて、このように考えることにより問題を単純化できる場合があります。
大きな問題をより簡単な問題の組み合わせに分解する考え方は分割統治と呼ばれ、再帰によって実現されます。別の例として、応用編の「ハノイの塔」があります。
文字列 "青森県" の文字数は 「 length("青森県") 」で参照でき、値は3となります。
toupper("This") は "THIS" になり、tolower("This") は "this" になります。
「2022/3/13」のような文字列があった時に、これを区切り文字「/」で分割するには次のようにします。結果は配列(この例では a )になります。
BEGIN{
yymmdd="2022/3/13"
a=split(yymmdd,a,"/")
print a[0] "年" a[1] "月" a[2] "日")
}
|
C>gawk -f split.awk 2022年3月13日 C> |
sumo.csv から「青森県出身者」のデータを抽出してみます。「 {print $0} 」は省略しても構いません。
BEGIN{ FS="," }
$2=="青森県"{ print $0 }
|
C>gawk -f syussin.awk 若乃花,青森県,177,105 栃ノ海,青森県,177,107 ... C> |
「2番目のフィールド($2)が『青森県』のレコードについて、当該レコード($0)を表示しなさい」という意味です。
次のようにしても結果は同じになります。
BEGIN{ FS="," }
$2~/青森県/{ print $0 }
|
ここで、「 〇〇~/ / 」は「〇〇が「 / / 」で表されるような文字列パターンにマッチしていれば...」と読みます。「 / / 」で囲まれた部分は「正規表現」と呼ばれます。
上の例は、「出身地に『青森県』という文字列が含まれている横綱を表示しなさい」という意味で、もしも出身地が「青森県弘前市」や「日本国青森県中津軽郡」のようなデータがあれば、それも表示されます。
正規表現を使うと、複雑な文字列パターンを簡潔に表現することができます。
下記は「名前の最後の文字が『山』であれば...」です。「 /山$/ 」の「 $ 」は「文字列の最後」を意味します。
|
|
C>gawk -f syussin.awk 佐田の山,長崎県,182,122 C> |
下記は「名前の先頭文字が『北』であれば...」です。「 /^北/ 」の「 ^ 」は「文字列の先頭」を意味します。
|
|
C>gawk -f syussin.awk 北の富士,北海道,185,135 北の湖,北海道,180,150 北勝海,北海道,181,144 C> |
少し複雑な例として、下記は「名前が『のノ乃』のいずれかを含み、そのあと何か1文字で終われば...」です。[ ] は、その中のどれか1文字、「 . 」は「任意の1文字」を表します。
|
|
C>gawk -f syussin.awk 若乃花,青森県,177,105 栃ノ海,青森県,177,107 佐田の山,長崎県,182,122 ... C> |
下記は、「名前が3文字で2文字目が『の』の人であれば...」です。
|
|
C>gawk -f syussin.awk 玉の海,愛知県,177,135 北の湖,北海道,180,150 隆の里,青森県,182,155 C> |
(練習) 名前が「海」または「山」で終わる横綱を表示しなさい。
(練習) 北海道出身で名前のどこかに「北」がつく横綱を表示しなさい。
gsub(r,s,文字列) は文字列の中の r を s に置き換える組み込み関数で、3番目の引数(文字列)を与えない場合は$0に対して置き換えが行われます。
|
|
実行すると下記のようになります。実行時に翻訳したいファイルを指定することもできますし、指定しなければキーボードからデータを入力するようになります。
C>gawk -f osaka.awk readme.txt ... C>gawk -f osaka.awk 本当ですか ホンマですか 本当にありがとうございました ホンマにおおきに ...^C C> |
上記の置き換えを拡張したものがこちらの本格的な(??)翻訳プログラムです。
(練習) gsub() を使い、「ですます体」の文書を「である体」に変換する整形プログラム dearu.awk を作りなさい。また、このプログラムで不都合が生じる例がないか考えてみなさい。
(練習) 上記を参考に、日本語文章をあなたの出身地の方言に変換するプログラムを作りなさい。
組み込み関数 rand() は0~1の一様乱数を返します(下図左 x=rand() )。はじめに srand() で系列を初期化してから利用します(そうしないと毎回同じ系列の乱数となります)。
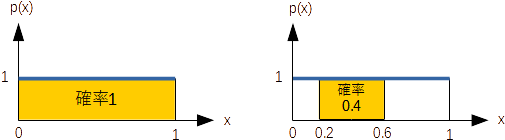
以下は、rand() で生成した10個の乱数を表示します。
|
|
C>gawk -f rand.awk 0.243829 0.176674 0.710108 0.581813 0.654712 0.169091 0.208045 0.519138 0.183928 0.52814 C> |
プログラムで何かの生起確率をコントロールしたい場合、例えば「確率0.4である表示をしたい」とすれば、rand() の値が0~1の間の0.4の幅に入っている場合に(上図では0.2~0.6)、その表示をするようにします。
以下は「おみくじ」のプログラムです。rand() の値が 0.9~1 の時に「大吉」(確率0.1)、0.6~0.9 の時に「吉」(確率0.3)、0.2~0.6 の時に「小吉」(確率0.4)、0~0.2 の時に「凶」(確率0.2)としています。
|
|
C>gawk -f omikuji.awk Enterキーを押してね(終了は何か文字を押してEnter) 小吉! Enterキーを押してね(終了は何か文字を押してEnter) 大吉!! ... |
以下はsumo.csvの中の横綱1名をランダムに抽出するものです。
|
|
C>gawk -f kuji1.awk sumo.csv 当選者は以下のとおりです 朝潮 C> |
当選者を5名とするにはどうしたらいいでしょうか。ENDの中の処理を5回繰り返せばいいと考えるかもしれませんが、そうすると重複の可能性が出てきます。
ライブラリ lib.awk には、shuffle() が定義されています(lib.awkはこちらからダウンロードできます)。この関数は、配列の要素をランダムに入れ換えます(Bentley:``Programming Pearls'' 11.3)。以下はこの関数を使って、sumo.csv の中から5人の名前を抽出するプログラムです。配列をランダムに入れ換えた後、先頭から5人を当選者とします。
|
|
C>gawk -f lib.awk -f kuji5.awk sumo.csv 当選者は以下のとおりです 若乃花 柏戸 ... C> |
実行結果は毎回異なります。
(練習) 「おみくじ」の確率を変えて実行してみなさい。また、「末吉」を追加してみなさい。
[1] プログラミング言語AWK, トッパン, 1989.
[2] 例題で学ぶ簡易言語「AWK」, トランジスタ技術 1991年6月号付録
| パターン{アクション} | |
| 関数定義 | |
| コメント | # から行末まで |
| BEGIN | レコードの処理前に1度マッチ |
| END | レコードの処理終了後に1度マッチ |
| 式 | $4>=150, $1~/山$/ など |
| /正規表現/ | $0~/正規表現/ の省略形。 |
| パターン1 && パターン2 | パターン1とパターン2の論理積(AND) |
| パターン1 || パターン2 | パターン1とパターン2の論理和(OR) |
| ! パターン | パターンの否定(NOT) |
| (パターン) | グループ化 |
| パターン1 , パターン2 | パターン1にマッチしてからパターン2にマッチするまで |
| 文の並び |
| 入出力文 | print文、printf文、getline文など |
| 制御文 | if文、for文など |
| 式 | x=0, 関数呼び出しなど |
| {文の並び} |
| getline | 次のレコードを $0 にセット |
| getline <file | fileの次のレコードを $0 にセット |
| getline 変数 | 次のレコードを変数にセット.NRとFNRもセット |
| getline 変数 <file | fileの次のレコードを変数にセット |
| 現在レコード $0 を表示 | |
| print 式の並び | 式の並びを表示 |
| print 式の並び >file | 式の並びをfileに保存 |
| printf 書式, 式の並び | 式の並びを書式に従って表示 |
| printf 書式, 式の並び >file | 式の並びを書式に従って保存 |
| system コマンド | Windowsのコマンドを実行(エラーレベルを返す) |
| close 式 | 入出力を閉じる |
| if(式) 文 | 式が真なら文を実行 |
| if(式) 文1 else 文2 | 式が真なら文1を実行、偽なら文2を実行 |
| while(式) 文 | 式が真である限り文を繰返し実行 |
| do 文 while(式) | 文を実行し、式が真である限り文の実行を繰返す |
| for(式1;式2;式3) 文 | 初めに式1を評価し、式2が真である限り文を実行しては式3を評価することを繰返す |
| for(変数 in 配列) 文 | 配列の添字をひとつずつ取り出しては変数に代入することをすべての添字について繰返す |
| break | forやwhileのループから抜け出す |
| continue | forやwhileのループ中の以後の処理をやめ、次のループに進む |
| next | |
| exit | プログラムを終了する |
| exit 式 | 式をエラーコードとしてプログラムを終了する |
| delete 配列要素 | 配列要素を削除する |
| 定数 | 数値定数または文字列定数 |
| 変数 | 数値か文字列 |
| フィールド変数 | $0 $1 ... $NF |
| 関数呼び出し | |
| 配列要素 | |
| (式) | 優先する演算の明示 |
| 演算子で式を結合したもの | |
| x=y | xにyの値を代入 |
| x++ | xの値を+1する |
| x-- | xの値を-1する |
| ++x | xに1を足してから値を返す |
| --x | xから1を引いてから値を返す |
| x+=y | xにx+yの値を代入 |
| x-=y | xにx-yの値を代入 |
| x*=y | xにx*yの値を代入 |
| x/=y | xにx/yの値を代入 |
| x%=y | xにx%yの値を代入 |
| x+y | 加算 |
| x-y | 減算 |
| x*y | 乗算 |
| x/y | 除算 |
| x%y | xをyで割った剰余 |
| + x | (単項)算術演算子 |
| - x | (単項)算術演算子 |
| x y | 文字列xと文字列yの連結演算(または連接演算)(演算子は明示されない) |
| ~/ / | 指定されたパターンにマッチ |
| !~/ / | 指定されたパターンにマッチしない |
| x==y | xとyが等しければ1(真),そうでなければ0(偽) |
| x!=y | xとyが等しくなければ1(真),そうでなければ0(偽) |
| x > y | x > yならば1(真),そうでなければ0(偽) |
| x < y | x < yならば1(真),そうでなければ0(偽) |
| x > =y | x > =yならば1(真),そうでなければ0(偽) |
| x < =y | x < =yならば1(真),そうでなければ0(偽) |
| x&&y | 論理積 AND: xが1(真)かつyが1(真)なら1(真), そうでなければ0(偽) |
| x||y | 論理和 OR: xが1(真)またはyが1(真)なら1(真), そうでなければ0(偽) |
| !x | 否定 NOT: xが0(偽)なら1(真), そうでなければ0(偽) |
| 式1 ? 式2 : 式3 | 式1が1(真)なら式2、そうでなければ式3 |
| ARGC | コマンド行の引数の数 |
| ARGV[ ] | コマンド行の引数の配列 |
| FILENAME | 現在の入力ファイル名 |
| ENVIRON["..."] | 環境変数の値 |
| FS | 入力のフィールド区切り文字(初めはスペースまたはタブ) |
| RS | 入力のレコード区切り文字(初めは改行) |
| NF | 現在レコードのフィールド数 |
| NR | 現在の通算レコード |
| FNR | 現在の入力ファイルの通算レコード |
| OFS | 表示のフィールド区切り文字(初めはスペース) |
| ORS | 表示のレコード区切り文字(初めは改行) |
| OFMT | 数の表示の書式(初めは「 %.6g 」) |
| RSTART | matchでマッチした文字列の開始位置 |
| RLENGTH | matchでマッチした文字列の長さ |
| $0 | 現在の入力レコード |
| $1,...,$NF | 第1フィールド,...,第NFフィールド |
| atan2(y,x) | atan(y/x) で -π~π の値. |
| sin(x) | sin関数 |
| cos(x) | cos関数 |
| exp(x) | exp関数 |
| log(x) | 自然対数 |
| sqrt(x) | 平方根 |
| sqrt(2)は1.414 | |
| int(x) | 小数点以下を切り捨て |
| int(3.14) は 3 | |
| int(-3.14) は -3 | |
| rand() | 疑似乱数 0以上1未満の一様分布 |
| srand() | 乱数の初期化( srand() を呼び出すと以後 rand() は毎回異なる乱数系列を生成する) |
| gsub(r,s,t) | 文字列 t の中に現れる文字列 r をすべて文字列 s で置換し、置換した数を返す。t を省略すると $0 が使われる。 |
| t="弘前大学教育学部";gsub("教育","医",t) で t は"弘前大学医学部" | |
| index(s,t) | 文字列 s の中の文字列tの位置。t が現れない場合は 0。 |
| length(s) | 文字列 s の長さ |
| length("弘前大学教育学部") は 8 | |
| toupper(s) | 文字列 s を大文字にした文字列 |
| toupper("This") は "THIS" | |
| tolower(s) | 文字列 s を小文字にした文字列 |
| tolower("This") は "this" | |
| match(s,r) | 文字列 s が文字列 r にマッチする位置。マッチしないときは 0。 |
| split(s,a,fs) | fsをフィールド区切り文字として文字列 s を配列 a に分解し、フィールド数を返す。 |
| sprintf(書式,式) | 書式で整えた式の並び |
| sub(r,s,t) | はじめの1回だけ置換する他、gsub()と同様。 |
| substr(s,i,n) | 文字列sのi番目から始まるn文字 |
| substr("弘前大学教育学部",3,2) は "大学" | |
| systime() | 現在の時刻 |
| strftime() | 時刻情報からの書式変換 |
| function 関数名(引数の並び){...} | 関数定義 |
| return | 関数から戻る |
| return 値 | 関数から戻り、値を返す |
| return 式 | 関数から戻り、式を値として返す |
| %c | ASCII文字 | "|%c|",65 | |A| |
| %d | 10進数 | "|%d|",65 | |65| |
| "|%5d|",65 | | 65| | ||
| "|%05d|",65 | |00065| | ||
| %e | [-]d.ddddddE[+-] | "|%e|",65 | |6.500000e+01| |
| "|%5.1e|",65 | |6.5e+01| | ||
| %f | [-]ddd.dddddd | "|%f|",65 | |65.000000| |
| "|%5.1f|",65 | | 65.0| | ||
| %g | e変換とf変換の短い方で無意味な0を表示しない | ||
| %o | 符号なし8進数 | ||
| %s | 文字列 | "|%s|","hirosaki" | |hirosaki| |
| "|%10s|","hirosaki" | | hirosaki| | ||
| "|%-10s|","hirosaki" | |hirosaki | | ||
| %x | 符号なし16進数 | ||
| %% | %そのもの | ||
| A | Aそのもの(以下の特殊文字を除く普通の文字) |
| ¥¥ | ¥そのもの |
| ¥" | "そのもの |
| ¥t | タブ |
| ¥n | 改行 |
| ¥f | フォームフィード |
| ¥b | バックスペース |
| ¥033 | 8進数033 |
| ^a | 文字列の先頭がa |
| a$ | 文字列の末尾がa |
| . | 任意の1文字 |
| [abc] | abcのどれか1文字 |
| [^abc] | abc以外の1文字 |
| [a-e] | abcdeのどれか1文字 |
| [^a-e] | abcde以外の1文字 |
| a* | 0個以上のaの並び |
| a+ | 1個以上のaの並び |
| a? | aが1個あるいは0個 |
| abc|de | abcまたは「de」 |
| (関数) | |
| max(i,j) | 大きい方の値 |
| min(i,j) | 小さい方の値 |
| rep(s,n) | 文字列sをn回繰り返した文字列 |
| randint(n) | 1~nのいずれか |
| randlet() | 'a'~'z'のいずれか |
| swap(buf,i,j) | 配列bufの要素iとjの入れ換え |
| shuffle(buf) | 配列bufの要素をシャフル |
| gettime() | 以下のyy()~SS()を使う前にgettime() |
| yy() | 年:19XX |
| mm() | 月:1~12 |
| dd() | 日:1~31 |
| aa() | 曜日:"Sun"~"Sat" |
| HH() | 時:0~23 |
| II() | 時:1~12 |
| MM() | 分:0~59 |
| SS() | 秒:0~59 |
| (定数) | |
| PI | πの値 |
| CHI1[1]~CHI1[30] | 有意水準1%のχ2乗表([ ]内は自由度) |
| CHI5[1]~CHI5[30] | 有意水準5%のχ2乗表([ ]内は自由度) |