図1 ショートカットのプロパティ設定
JupyterLab Desktop のインストーラをここからダウンロードし、実行します。すべてデフォルトでインストールします。インストールについては、こちらやこちらの解説を参考にしてください。
ドキュメントフォルダに Python というフォルダを作成し、これから作るプログラムはこの中に置くことにします。このフォルダのショートカットをデスクトップに作成し、Python とします。
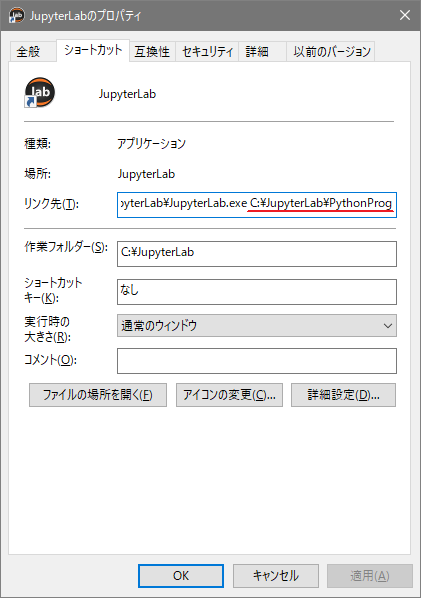
「C:¥JupyterLab¥JupyterLab.exe」のショートカットをデスクトップ(またはスタートメニュー)に作成し、JupyterLab とし、右クリックでプロパティを開き、リンク先に「C:\JupyterLab\JupyterLab.exe C:¥Users¥ユーザ名¥Documents¥Python」のように先ほど作ったPythonフォルダのパス名を追記します(下図)。
メニューの日本語化は
の後、再起動し、[settings][Language]で「日本語」を選択します。
プログラミング言語はコンピュータが理解できる特別な言葉です。プログラミング言語を使ってコンピュータにさせたい仕事を記述したものがプログラムです。プログラミング言語には多くの種類があり、目的によって使い分けられますが、ここでは、Pythonというプログラミング言語を用いてプログラムを作成します。
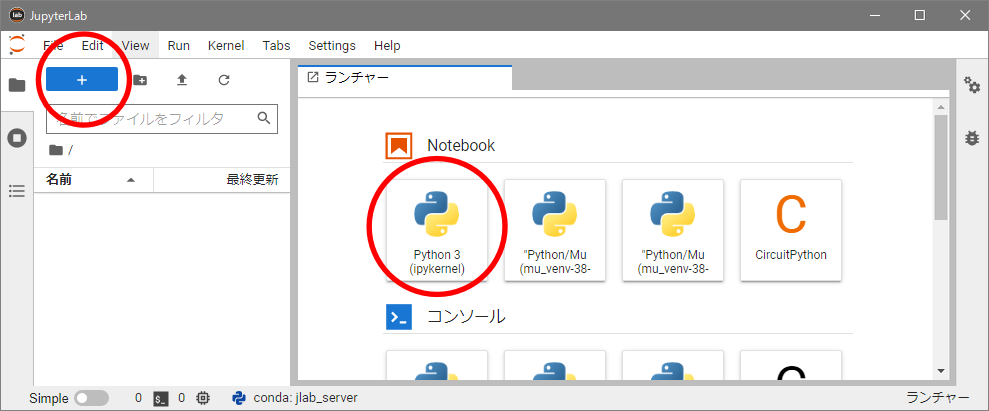
JupyterLabを起動し、「+」でランチャーから Notebookの「Python3」を選択してください(下図)。
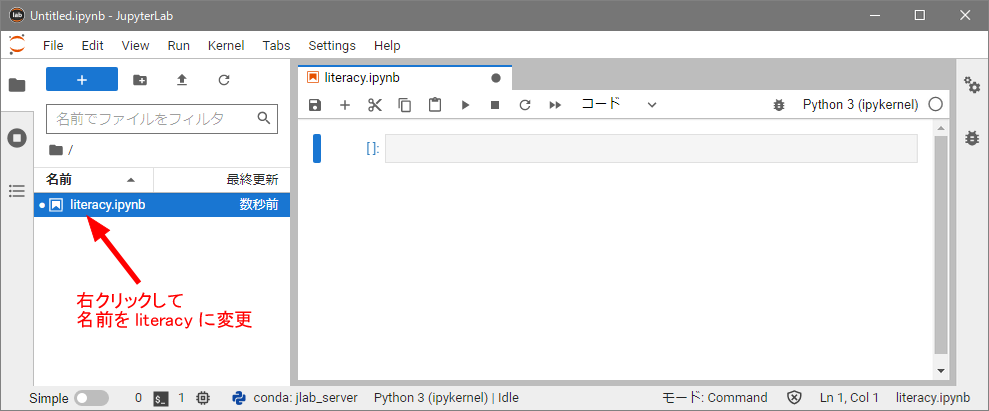
ファイル名が「Untitled.ipynb」となっているので「literacy.ipynb」に変更してください(下図)。
画面右の「セル」をマウスで選択し、「print("Hello")」とプログラムを入力し、Shift + Enter を押すと、プログラムが実行され、「Hello」の表示が現れます(下図)。なお、引き続き新しいセルを作成したり、遡って前のセルを選択して実行したりしますが、プログラムはセル単位で実行され、セルの左には [1]: のように実行の通し番号が表示されます。
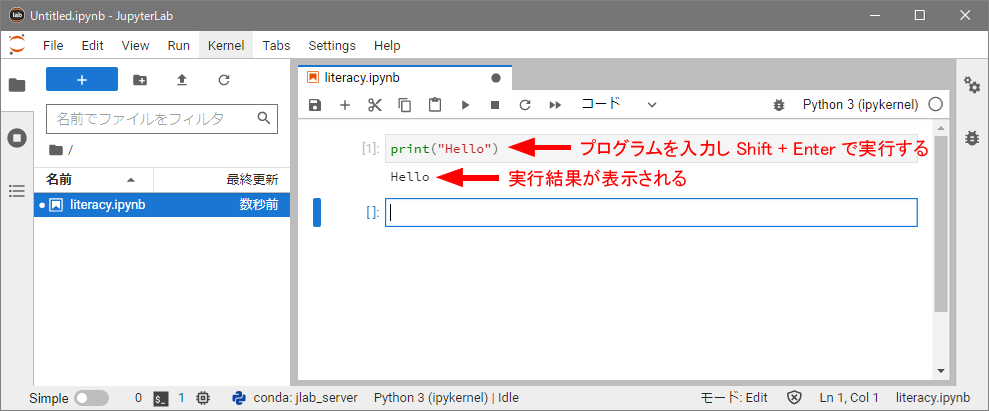
print(...)は「文字を表示しなさい」というPython言語の命令語で、「プログラムが正しく解釈されて実行された」わけです。
なお、PythonProg フォルダを開き、中に literacy.ipynb があることを確認してください。ファイルは自動保存されます(デフォルトでメニューバーの[Setting][ドキュメントの自動保存]がチェックされています)。
(練習) プログラム中の「Hello」の部分を「こんにちは」に替えて、プログラムを実行してみなさい。
プログラム中に「 # 」が現れると、以後行末までコメントとなります。コメントはプログラムの実行に影響せず、プログラムの説明などを書きます。後から見直す時のために、次のように積極的にコメントを入れるようにします。
|
|
プログラムを作っても、意に反してうまく動作しないことはしばしばです。プログラムを作ったら、まずは思ったとおりにそのプログラムが動作しているかどうかを調べ、もしもうまく動作していなければ誤りを見つけて修正しなければなりません。
ここで、[1]のセルを選択し、
|
|
のように、末尾の「 ) 」を取って(入力し忘れて)、実行(Shift + Enter)してみてください。すると、文法エラーとなり、誤りが指摘されます(下図)。ただし、いつも的確な表現で指摘してくれるとは限らないので、注意が必要です。なお、この時点で実行の通し番号は[2]となります。
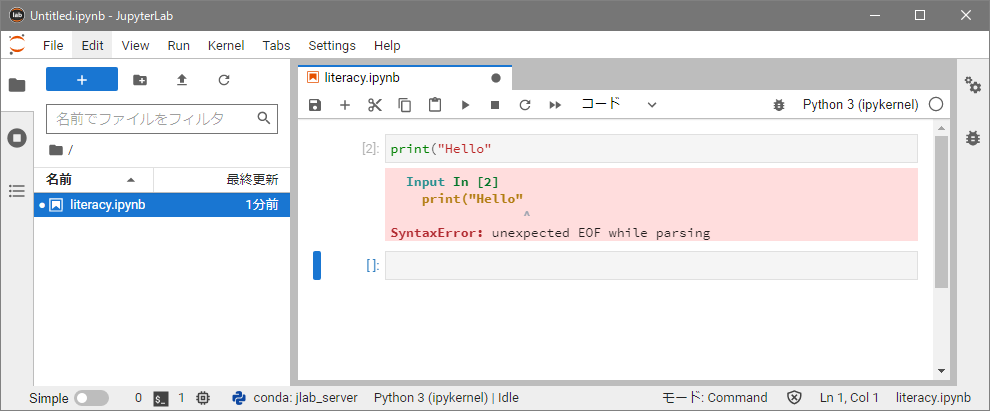
プログラムが正しく動作しない場合は、誤りの箇所を探し、修正して再度動作を確認します。正しく動作するようになるまで
| → |
|
(練習) プログラムを次のようにわざと間違えて実行してみなさい。
肥満の判定に用いられるBMI(Body Mass Index)は次式で計算します。ただし、単位は身長[cm]、体重[kg]。
この値は下表のように判定されます。
| 19.8未満 | 19.8以上24.2未満 | 24.2以上26.4未満 | 26.4以上 |
| やせ | 普通 | 過体重 | 肥満 |
ここで、図2の「+」でランチャーから Notebookの「Python3」を選択してください。新しいプログラムになるので、ファイル名「bmi.ipynb」にしてください。タブの操作で前のプログラム literacy.ipynb と、簡単に切り替えられます。
身長が170cm、体重が65kgの人のBMIを計算するPythonプログラムをセルに入力し、実行してみます(下図)。
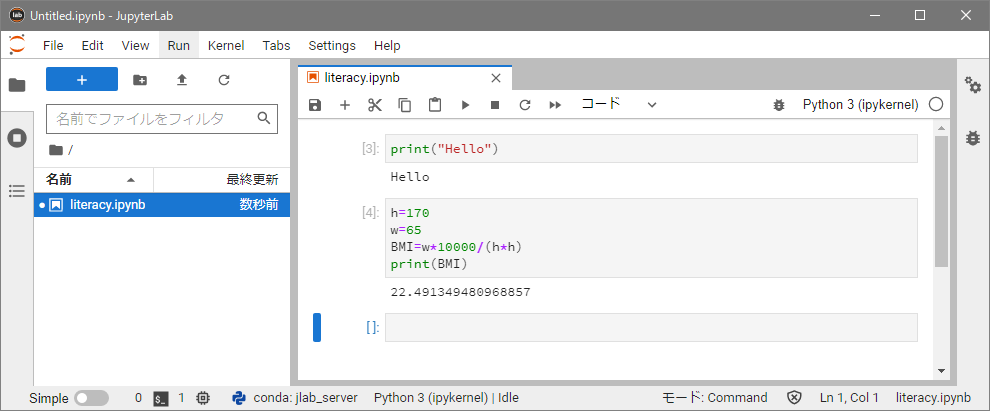
入力したプログラムは、初めに変数 h(身長)に 170 を代入し、次に変数 w(体重)に 65 を代入します。「 = 」は左辺と右辺が等しいということではなく、「右辺の値を左辺(の変数)に代入しなさい」という意味です。次に、h と w の値からBMIを計算し、変数 BMI に代入します。
実行結果が「22.4913...」のように表示されます。
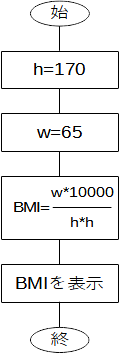
4行からなるプログラムの各行はPython言語で表された文で、「...しなさい」という命令を表しています。プログラムは文の並びで構成され、基本的には記述した順に実行されます。ですから、プログラムとは「動作の手順を記述した書き物」ということができます。上のプログラムをフローチャートで表せば下図のようになります。
1行に2つ以上の文を記述する場合は、「 h=170; w=65 」のように、文の末尾(文と文の間)に「;」を置きます。
2.4でエラーとデバグについて書きましたが、文法エラーとは別の種類の誤りもあります。それは、BMIを計算する際に「10000」を「1000」と入力したような場合です。このような場合はコンピュータにとって誤りではなく、指示どおりに「正しく」計算し、その結果1桁違った結果が表示されることになります。このようなプログラム作成者の入力ミスや考え違いによって生じるエラーには特に注意が必要です。
(練習) プログラム中の「10000」の箇所を「1000」として、動作を確認しなさい。
変数はデータを入れる「箱」のことで、名前(変数名)が付けられます。宣言せずに突然変数を使いはじめることができ、0または空文字列("")に初期設定されます。変数名は、アルファベットで始まる英数文字列で、大文字と小文字は区別されます。大文字の変数名には、組み込み変数として使われているものもあるので、なるべく小文字を使います。
「h=170」は、hという名前の変数に170という数値データを代入します。データの型には数値の他に、文字列や論理値があり、変数にはどちらの型のデータも代入できます。他の多くのプログラミング言語では、あらかじめ変数の使用を宣言したりデータの型を指定する必要があります。数値は整数と浮動小数点数が区別なく扱われます。
変数 s に文字列データを代入する場合は、
のように、文字列データの部分を「 ' (引用符)」または「 " (二重引用符)」で囲みます。
論理値は True (真)または False (偽)いずれかの値をとります。
「 BMI=w*10000/(h*h) 」は、h の値と w の値からBMIを計算して変数 BMI に代入します。乗算を示す「 * 」や除算を示す「/」を演算子といいます。
「 5+10 」や「 x-y 」などは式と呼ばれ、演算子に従って左右の値に対して演算が行なわれ、その演算結果が式の値となります。式を組み合わせた場合には、どの演算から順に計算されるかは演算子の優先度により決まります。優先して計算させたい箇所は、「 BMI=w*10000/(h*h) 」のように ( ) で括ります。 [ ] や { } などの括弧は利用できず、二重三重にする場合もすべて ( ) を使います。「 = 」は代入演算子です。
文字列の演算には連結演算(または連接演算)があります。二つの文字列をくっつけて一つの文字列にする演算で、演算子は加算と同じ「 + 」を使います。たとえば、「"標準" + "体重"」の演算結果は「"標準体重"」になります。次の例では、変数 z の値が「"標準体重"」という文字列になります。
さて、プログラムを次のように変更して、動作を確認してください。
h=170
w=65
BMI=w*10000/(h*h)
print("BMIは"+str(BMI))
|
変数 BMI には数値が代入されています。str(...)で文字列に変換し、文字列の連結演算が行なわれ、「"BMIは22...."」のような文字列となり、表示されます。
また、図2の「+」でランチャーから Notebookの「Python3」を選択し、ファイル名を「big.ipynb」にしてください。
数値の大小関係を調べるには、関係演算子を用います。「 h >= 180 」は身長( h )が 180 [cm]以上の場合に True(真)、そうでない場合は False(偽)になります。TrueやFalseは論理値です。
h=170 w=65 print(h>=180) |
等しいかどうかを調べるには、「h == 180」のように「 == 」を用い、その値はTrue(真)またはFalse(偽)となります。「h = 180 」のようにすると h に 180 が代入され、式の値は 180 になってしまいます。
関係演算子は文字列にも適用され、「 "ABC" == "ABC" 」「 "A" < "ABC" 」「 "A" < "B" 」などがTrue(真)となります。「 "10" < "2" 」もTrue(真)となるので注意が必要です。
(練習) h(身長)を 190 にして動作を確認しなさい。
(練習) w (体重)が 80 以上かどうか調べるようにし、w の値を変えて動作を確認しなさい。
論理式や論理値を組み合わせて複雑な条件を表現するには「and」「or」「not」の論理演算子を用います。
「 h>=180 or w>=70 」は、身長( h )が 180 [cm]以上かまたは体重( w )が 70 [kg]以上の場合に変True(真)、そうでない場合はFalse(偽)になります。
h=170 w=65 print(h>=180 or w>=70) |
実際にはこのように論理値をそのまま表示させることはなく、比較演算や論理演算は主に後出のif文やfor文の条件を表現する際に用います。
論理演算の入力と出力の関係を表で表せば以下のようになり、これを真理値表といいます。
|
|
(練習) h(身長)や w(体重)を変えて動作を確かめなさい。 (練習) h (身長)が180以上かつw (体重)が70以上の時に True が表示されるようにし、h や w の値を変えて動作を確認しなさい。 6. 入出力6.1 文字出力これまでは、print( )という関数を使い、文字を表示してきました。
6.2 文字入力タブで bmi.ipynb を選択してください。 これまでは、プログラムの中で身長や体重の値を決めていましたから、いつも同じBMIの値が表示されても、あまり利用価値はありません。そこで、このページを見る人が自分の身長や体重を入力できるようにしてみます。
input( )という組み込み関数は、引数として渡された「"身長?"」「"体重?"」などの文字列を表示し、入力欄への文字入力を促します。入力欄に入力した値(文字列)は、input( )の値(戻り値)となり、h や w に代入されますinput( )は文字列値を返すので、int()で整数に変換しています。 (練習) BMIの正常値は、標準値22の±10%の範囲、つまり19.8以上24.2未満とされています。(1)身長を入力すると望ましい体重(BMIが22の時の体重)を表示するプログラムを作りなさい。(2)身長を入力すると「あなたの望ましい体重は○○~○○kgです」のように表示されるように変更しなさい。 7. 関数7.1 組み込み関数の利用これまで、既に print( )、input( )、str( )、int( ) などの関数を使ってきました。これらはPython言語に予め用意されている関数で、組み込み関数と呼ばれます。 以下のように、round( ) という小数点以下で四捨五入する関数を使ってみます。通常の四捨五入とはちょっと違うようですが、ここでは触れません。
この場面では、小数点以下1桁まで表示させたいので、以下のようにします。
7.2 関数の定義と呼び出し組み込み関数と同じように使えるオリジナルの関数を作ることができます。以下では、bmicalc( ) という関数を新たに定義し、利用しています。
「 def bmicalc(h,w):... 」では bmicalc という関数を定義し、「 BMI=bmicalc(h,w) でその関数を呼び出し、戻り値を利用しています。関数定義は
のように書き、字下げ(インデント)された箇所がその関数定義の範囲となります。引数の並びは「 , (カンマ)」で区切ります。引数が無い場合もあります。 関数定義の中が複数の文からなる場合は順に実行され、最後まで実行するか、またはreturnが現れると、呼び出された箇所に戻ります。上の例のように、
を実行すると「値」を関数の値として戻ります。戻り値を必要としない場合もあります。 プログラムは順に実行されるのですが、関数定義の部分は例外で、その関数が呼び出されたときに実行されます。 つまり、この例では、まず「 h=int(input("身長")) 」と「 w=int(input("体重")) 」が順に実行され、次に「 BMI=bmicalc(h,w) 」で bmicalc( ) を呼び出します。そのときに h と w の値が引数として関数に渡され、それぞれ関数定義部分の h と w の変数に代入されます。bmicalc の関数では「 x=w*10000/(h*h) 」でBMI値が計算され変数 x に代入されます。「 x=round(x*10)/10 」で x の値が小数点以下1桁に修正され、return でその値が bmicalc( ) の戻り値となります。 この例では定義した関数を1度しか呼び出していませんが、関数を複数箇所で呼び出すような場合に関数の定義が効果を発揮します。 なお、BMI は局所変数となり、変数 BMI はこの関数内でのみ有効となり、関数定義以外の箇所で同じ変数名xを使っても、異なる変数として扱われます。関数定義の中で新しく表れた変数は局所変数となります。
8. 条件分岐: if文BMI値が26.4以上の場合「肥満」と判断されます。新しいセルに次のように入力し、動作を確認してください。
( )内がTrueの時(この場合は「 BMI>=26.4 」がTrueの時)に●が表示されます。 if文は
と書き、式がTrue(真)の時に文が実行されます。この例では「 BMI>=26.4 」がTrueの時に●付のBMI値が表示されます。フローチャートで表せば、一般には下図左、ここでの例に関しては同図右となります。 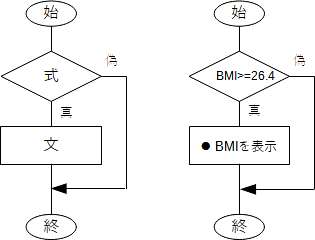 図7 条件分岐(1) しかし、このままでは、「 BMI>=26.4」がTrueでない場合には何も表示されません。その場合は●なしでBMI値だけを表示するには else を使い次のようにします。
この場合のif文は if 式: 文1 else: 文2と書き、フローチャートで表せば、一般には下図左、ここでの例に関しては同図右のようになります。 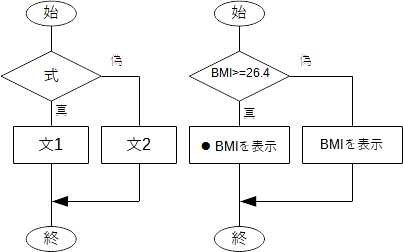 図8 条件分岐(2) このように、条件によって処理の内容を変えることができます。もしも、ある条件を満たしたとき、あるいはそうでないときに、複数の文を実行させたい場合は次のようにします。 上の例では、if文を使って2つの場合分けをしたわけですが、もっと細かく場合分けしたいこともあります。BMI値が26.4以上ならば●、24.2以上26.4未満ならば○、19.8以上24.2未満ならば◎、19.8未満ならば△をそれぞれ表示させてみましょう。●については既に正しく動作するので、「 BMI>=26.4 」がFalseの場合について elif (else if)を使って更に場合分けをします。
フローチャートで表せば、下図のようになります。例えば「〇」の表示は、BMIが26.4未満24.2以上であることがわかります。 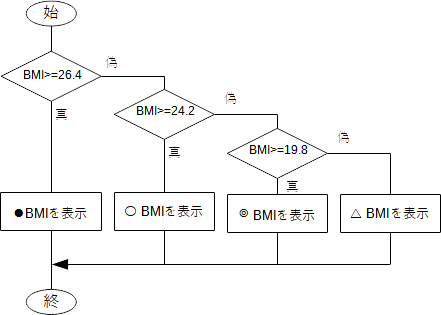 図9 複数の場合分け ここで、関数定義の復習になりますが、BMIの値に応じた記号を返す関数 mark( ) を定義し、次のようにしてみます。関数定義を使って機能を独立させることにより、プログラムの見通しが良くなります。
(練習) 身長や体重の入力欄が空( "" )の時に値の入力を促すようにしなさい。 (練習) ●○◎△の記号ではなく、メッセージを表示するようにしなさい。 9. 繰り返し: while文とfor文9.1 while文以下は、はじめに身長を入力し、その身長に対するBMIの値を体重5kgきざみで計算して表示するプログラムです。
入力した身長に対するBMIの値が、体重5kgきざみでページ中に表示されます。 while文は
と書き、( ) 内の「式」がTrueである限り何度でも、「文」を繰り返し実行します。フローチャートで表せば、一般には下図左、ここでの例に関しては同図右のようになります。 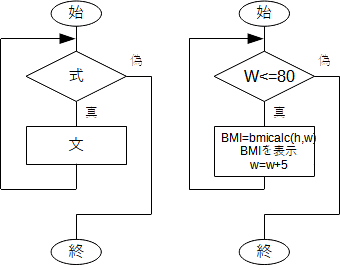 図10 繰り返し(while文) 初めに w を 40 にしています。そして、「 w<=80 」がTrue(真)である限り字下げされた範囲を繰り返し実行します。その最後で w の値を 5 ずつ増やしているので、w はいずれ 85 になり、その時点で条件を満たさなくなり、繰り返しを終了します。 9.2 for文上の例のように、繰り返しのプログラムでは、初期化( w=40 )と条件調べ( w<=80 )と更新( w=w+5 ) の3点セットが頻繁に登場します。この部分をまとめて書くようにしたのがfor文です。上の例はfor文を使って次のように書くことができます。動作は同じです。
for文は
と書き、典型的な繰り返し範囲は range(初期値,限界値,ステップ) のように書きます。はじめに変数を初期値(省略時は0)にし、限界値に達しない範囲でステップ(省略時は1)ずつ変化させながら文を繰り返し実行します。フローチャートで表せば、一般には下図左、ここでの例に関しては同図右のようになります。 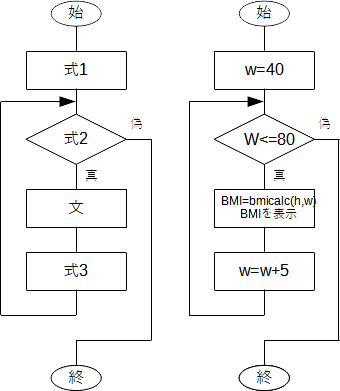 図11 繰り返し(for文) (練習) 正の整数を入力し、1からその値まで足した値を表示するプログラムをつくりなさい。 (練習) 半径に対する面積と体積の表を作りなさい。 10. 配列と連想配列10.1 配列ランチャーから Notebookの「Python3」を選択し、ファイル名を「sumo.ipynb」にしてください。 5人の横綱の身長が、変数 h1 ~ h5 に用意されている時に、平均身長 mh を求めて表示するプログラムは以下のようになります。
では、5人ではなくて100人だとどうでしょうか。h1~h100に値が用意されていたとしても、それらは別々の変数なので、その平均を求めるためには以下のようにすべての変数名を明記しないといけません。
これは現実的ではありません。 このように、データ数が多い場合は変数の一種である配列を使います。配列の場合、ひとつの変数に複数のデータを格納できます。
のように値を代入すると、1番目のデータ 178 は h[0]、2番目のデータ 177 は h[1] で参照できます。[ ] 内の番号を添え字(index)といいます。添え字は0から始まることに注意してください。
のようにまとめて代入することもできます。 配列を使うと、順番にデータを扱うことが可能になり、for文で配列要素をhにひとつずつ取り出し、次のように平均身長を求めることができます。
100人分のデータであったとしても(それをどうやって用意するかは別にして)、プログラムは5を100に替えるだけですみます。 上の例では、5人の横綱の身長だけを扱いましたが、5人の横綱の「名前, 出身地, 身長, 体重」のデータを扱いたい場合はどうしたらいいでしょうか。このような場合は以下のように2次元配列を使います。
のように配列データを作ると、sumo[0] の値は ["栃錦","東京都",178,127] という配列になり、栃錦の身長 178 はその3番目の要素なので sumo[0][2] で参照できます。 なお、上のように配列が用意されている場合、そのサイズ(要素数)は len(sumo) で参照でき、この例では 5 になります。また、len(sumo[0]) は 4 になります。 この場合、横綱の平均身長を求めて表示するプログラムは以下のようになります。プログラム中のデータ数の箇所を「5」ではなく len(sumo) にしたのは、こうしておくと今後データが追加された場合もプログラムを変更せずにすむからです。
(データファイルの分離)上記のような2次元配列で、歴代横綱の名前、出身地、身長、体重のデータを sumo.csv というファイルに用意しました。こちらからダウンロードしてください。テキストエディタで sumo.csv を開いて確認してください。このファイルは sumo.ipynb と同じフォルダに入れ、次のように利用します。
以下は、すべての横綱についてBMIを計算して表示するプログラムです。
10.2 連想配列配列の添え字は0~の番号でしたが、添え字を文字列で扱うのが連想配列です。 横綱の体重データを
のように用意すると、栃錦の体重127は w["栃錦"] で参照できます。
のようにまとめて代入することもできます。 w={...} のように括弧の形が [...] ではないので注意してください。 以下の例では、はじめのfor文で sumo.csv のデータを読んで連想配列 w を作ります。そして、次のfor文「 for name in w 」で連想配列 w の添え字がひとつずつ name に代入され、print が繰り返されます。
以下は、すべてのデータを表示するのではなく、名前を入力するとその横綱の体重を表示するようにしたものです。
while True: ... の箇所は、インデントされた範囲を何度でも繰り返します。input( ) で入力した文字列が変数 name に入ります。次に、入力した文字列が空文字列の時(改行のみ行った場合)に break で while から抜け出ます。通常は、入力した名前がデータにあるかを「 if name in w 」で調べ、あれば名前と体重をアラート表示し、なければ「ありません」を表示します。 以下は、連想配列を使って出身地別の人数を数えて表示するプログラムです。
はじめのfor文で、配列 sumo のすべての横綱について、その出身地を添え字とする連想配列 ninzu の値に 1 を加えます。全レコードを読み終わった時点で、ninzu["青森県"] は 5、ninzu["長崎県"] は 1、...になっています。 そして、次のfor文で、ken に連想配列 ninzu の添字がひとつずつ代入され、document.write が繰り返されます。 データを読んでみないとどのような出身地が現れるかわからないわけですが、うまく処理することができます。 11. 関数: 再帰による関数定義前項で、出身地別に人数を表示することができましたが、これを簡易棒グラフで表示してみましょう。人数分だけ横に*印を並べることにします。プログラムは次のようにします。
定義した関数 rep(a , n) は a という文字列を n 個繰り返した文字列を返すようになっています。"A"*4 は "AAAA"、"AB"*3 は "ABABAB" を返します。 大きな問題をより簡単な問題の組み合わせに分解する考え方は分割統治と呼ばれ、再帰によって実現されます。別の例として、応用編の「ハノイの塔」があります。 12. 文字列の処理と正規表現文字列 "青森県" の文字数は 「 len("青森県") 」で参照でき、値は3となります。 toupper("This") は "THIS" になり、tolower("This") は "this" になります。 12.1 文字列の分割「2022/3/13」のような文字列があった時に、これを区切り文字「/」で分割するには次のようにします。結果は配列(この例では a )になります。
12.2 文字列の検索sumo.csv から「青森県出身者」のデータを抽出してみます。「 {print $0} 」は省略しても構いません。
「2番目のフィールド($2)が『青森県』のレコードについて、当該レコード($0)を表示しなさい」という意味です。 次のようにしても結果は同じになります。
ここで、「 〇〇~/ / 」は「〇〇が「 / / 」で表されるような文字列パターンにマッチしていれば...」と読みます。「 / / 」で囲まれた部分は「正規表現」と呼ばれます。 上の例は、「出身地に『青森県』という文字列が含まれている横綱を表示しなさい」という意味で、もしも出身地が「青森県弘前市」や「日本国青森県中津軽郡」のようなデータがあれば、それも表示されます。 正規表現を使うと、複雑な文字列パターンを簡潔に表現することができます。 下記は「名前の最後の文字が『山』であれば...」です。「 /山$/ 」の「 $ 」は「文字列の最後」を意味します。
下記は「名前の先頭文字が『北』であれば...」です。「 /^北/ 」の「 ^ 」は「文字列の先頭」を意味します。
少し複雑な例として、下記は「名前が『のノ乃』のいずれかを含み、そのあと何か1文字で終われば...」です。[ ] は、その中のどれか1文字、「 . 」は「任意の1文字」を表します。
下記は、「名前が3文字で2文字目が『の』の人であれば...」です。
(練習) 名前が「海」または「山」で終わる横綱を表示しなさい。 (練習) 北海道出身で名前のどこかに「北」がつく横綱を表示しなさい。 12.3 文字列の置換gsub(r,s,文字列) は文字列の中の r を s に置き換える組み込み関数で、3番目の引数(文字列)を与えない場合は$0に対して置き換えが行われます。
実行すると下記のようになります。実行時に翻訳したいファイルを指定することもできますし、指定しなければキーボードからデータを入力するようになります。 上記の置き換えを拡張したものがこちらの本格的な(??)翻訳プログラムです。 (練習) gsub() を使い、「ですます体」の文書を「である体」に変換する整形プログラム dearu.py を作りなさい。また、このプログラムで不都合が生じる例がないか考えてみなさい。 (練習) 上記を参考に、日本語文章をあなたの出身地の方言に変換するプログラムを作りなさい。 13. 乱数の利用random() は0~1の一様乱数を返します(下図左 x=random() )。 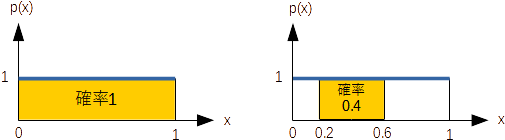 図 一様分布(左)と生起確率のコントロール(右) 以下は、random() で生成した10個の乱数を表示します。
プログラムで何かの生起確率をコントロールしたい場合、例えば「確率0.4である表示をしたい」とすれば、random() の値が0~1の間の0.4の幅に入っている場合に(上図では0.2~0.6)、その表示をするようにします。 以下は「おみくじ」のプログラムです。random() の値が 0.9~1 の時に「大吉」(確率0.1)、0.6~0.9 の時に「吉」(確率0.3)、0.2~0.6 の時に「小吉」(確率0.4)、0~0.2 の時に「凶」(確率0.2)としています。
以下はsumo.csvの中の横綱1名をランダムに抽出するものです。
当選者を5名とするにはどうしたらいいでしょうか。ENDの中の処理を5回繰り返せばいいと考えるかもしれませんが、そうすると重複の可能性が出てきます。 shuffle() は、配列の要素をランダムに入れ換えます。以下はこの関数を使って、sumo.csv の中から5人の名前を抽出するプログラムです。配列をランダムに入れ換えた後、先頭から5人を当選者とします。
実行結果は毎回異なります。 (練習) 「おみくじ」の確率を変えて実行してみなさい。また、「末吉」を追加してみなさい。 付録A. Python言語のまとめ□ 代表的な演算子
□ 関数と定数
□ 制御文
|